
Is “narrow” AI dead? The implications of SAP-RPT-1 for Business AI & Data Scientists
This week our team attended SAP TechEd in Berlin where SAP unveiled their latest foundation model called SAP-RPT-1 (read as “Rapid-1”). Some further information on this announcement is given in A New Paradigm for Enterprise AI: In-Context Learning for Relational Data as well as their official paper published at this year’s NeurIPS conference ConTextTab: A Semantics-Aware Tabular In-Context Learner. It is available for exploration on the SAP-RPT-1 Playground – and therefore our team already performed experiments with this model. The key question we’re asking is: What exactly does this mean for businesses, executives and Data Scientists who over the last years have introduced countless narrow AI models delivering business value? Niklas Frühauf, Senior Data Scientist at sovanta, summarized our team’s findings in this blog post.
We start with a short background information: “Narrow” AI is the SAP term for Machine Learning (ML) models trained on customer-specific data to fulfil a specific task (“forecast my sales for the next quarter based on the historic evolution”), in contrast to foundation models that offer out-of-the box transfer learning and are thus applicable to a wide range of tasks. Thus, introducing RPT-1 fits well to the SAP vision of introducing low-code solutions to enable business or non-data scientist users to quickly get up to speed with AI-powered business solutions that go beyond LLM capabilities.
The strategic messaging is clear – custom or narrow AI models are no longer needed, as foundation models can fulfil the task just as well or better. But is this really the case?
In this blog post, we will try to give some important context on that announcement. Within sovanta we have more than ten years of condensed (SAP) AI experience. Our AI Squad works every day with SAP AI technologies, exploring their business impact. In the next section, we’ll address three key questions:
- What are the strategic implications for SAP customers and Data Scientists?
- What are some important shortcomings of the approach businesses and Data Scientists need to be aware of?
- What does SAP-RPT-1 mean for me as a Data Scientist, and when should I (not) use it?
Foundation Models for Text vs. Relational / Tabular Data
Let’s start with some basics. Just like Large Language Models (LLMs) are “foundation models” that are pre-trained to generate text based on previous text blocks (“prompts”) on terabyte of text data, RPT-1 is a “foundation model” that is pre-trained on millions of different relational datasets to generate values for one or more cells given surrounding cells.
The idea is not new, as libraries such as TabPFN have garnered more and more attention over the last year, showcasing promising results. In fact, RPT-1 seems to be an enhanced version of the TabPFN architecture, extended especially with capabilities that allow it to (a) understand column names and (b) learn from text values within dataset cells. Coincidentally, TabPFN just yesterday announced version 2.5, claiming SOTA (state-of-the-art) on a couple of benchmarks as well – sadly, the technical report does not allow a direct comparison between these two.
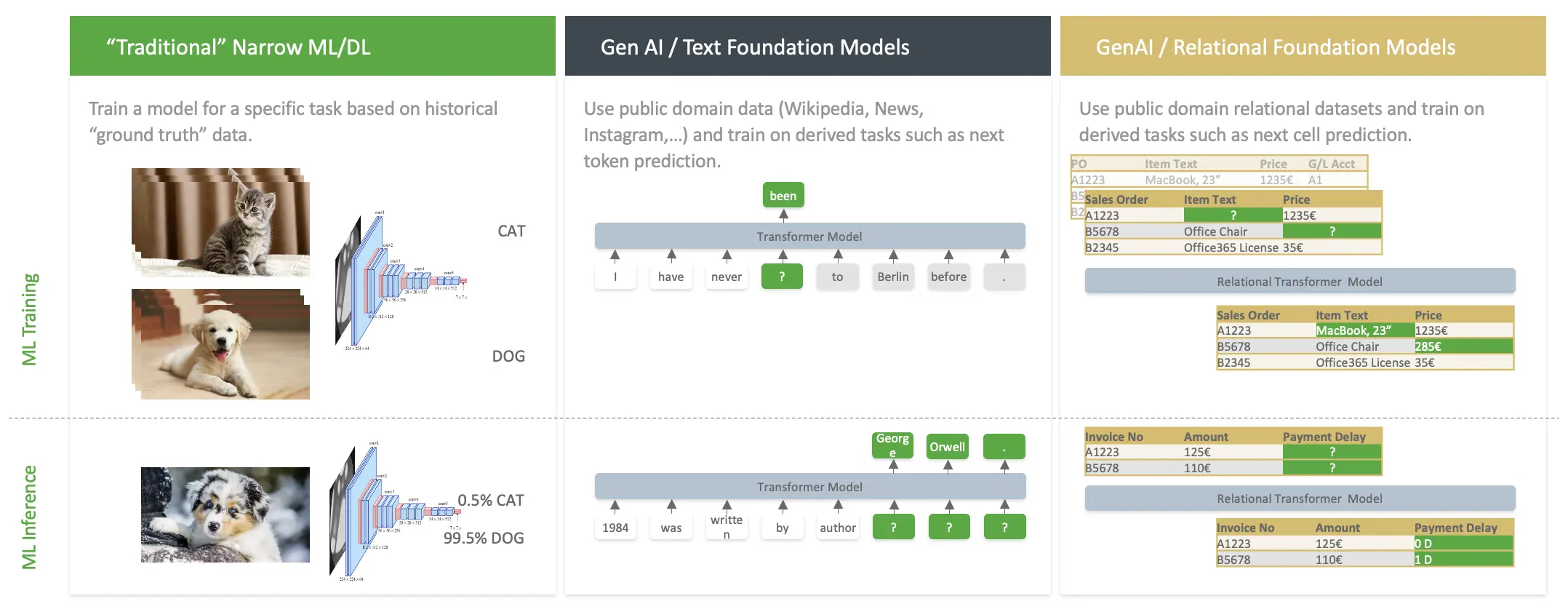
The inherent advantage of this is clear: In the same way as an LLM learns basic rules of natural language and common knowledge from its vast amounts of (textual) data during training, RPT-1 learns important concepts of tabular data: dependencies between different columns and cell values, the importance of column names and, most importantly, it has most likely also understood what a sales or service order is, and that price usually depends on the quantity and item types. The idea is simple: we can mask out any cell in a table and have RPT-1 predict its value, requiring only a handful of example rows as context.
In such a way, RPT-1 can be understood similarly as a “few-shot” LLM prompting approach. If you ask an LLM to assign tickets to correct recipients given their textual contents, you would include some real-world examples and their desired recipients as few-shot examples. That would “teach” the LLM which people exist, and which person is responsible for what – all within a prompt, not requiring any training step.
For RPT-1, the handful of “context” rows that you provide take over the role of these examples above, giving RPT-1 a glimpse on what your tabular data looks like and establishing boundaries for their task. You then ask it to predict outcomes (e.g. the time it will take a customer to pay his invoice, the category for a ticket, etc.).
The Strategic Vision of SAP-RPT-1
The advantages are obvious. In an ideal scenario, we no longer need to hand-craft complex AI models, spending weeks on iterating different approaches, running hyperparameter sweeps, and so on. That would further mean that we no longer need Data Scientists working in Python to package their models into REST APIs, just so that they can be consumed from our business apps running in CAP on Cloud Foundry. Instead, the “new” Data Scientists would focus on understanding stakeholder demand, preparing data sets and key features, and then implement the forecasting pipeline in CAP, simply accessing the available RPT-1 model via the SAP Generative AI Hub.
Moreover, this would enable forecasting scenarios without a large amount of training data – which previously was impossible to realise as hand-labeling data is time-consuming and expensive.
However, a key factor remains: AI scenarios will require a business case behind them and this requires understanding how reliable the AI forecasts are, what value they create, and the associated costs. In our eyes, we still need Data Scientists that can translate business requirements and domain knowledge into inputs for foundation models, and more importantly evaluate / back-test how well such a foundation model works for a given use case, translating that into KPIs that business stakeholders can understand. If stakeholders are happy with the measured accuracy, we no longer have to spend months on hand-crafting a narrow AI model. But if for some reason the model does not work well, we need to know its limitations before moving it into production. In the same sense that Generative AI-based solutions for text require an evaluation strategy to measure if it works well enough, RPT-1 requires an example dataset to ensure it meets business demands.
What are the Shortcomings and Quirks of Tabular Foundation Models?
However, it is important to understand that this also comes with some of the inherent flaws of other foundation models (such as LLMs). It is important to note that some of these “flaws” are not an issue with RPT-1 in specific, but instead a result of the contextual learning paradigm that also affected related models such as TabPFN.
Firstly, the lack of explainability. With the EU AI Act mandating strict rules for high risk areas – such as credit ratings in a finance or banking context – even traditional narrow AI models (Gradient Boosting) were often called a “black box” or “impossible to explain”. Yes, you would be able to leverage packages such as SHAP to calculate local feature impacts, but these would only ever provide an approximation. With relational foundation models such as RPT-1, this becomes even more infeasible: We have no way of understanding how a specific forecast comes into being. That will most likely rule out any applications in areas where explainable AI, calibrated probabilistic outcomes or bayesian modeling are currently used. Luckily, SAP has these items well on their roadmap, and we are curious on how post-processing steps and others can be used to address these concerns.
Secondly, the lack of reproducibility and sensitivity to data ordering. Yes, RPT-1 will provide the same outputs twice if given the exact same context and task. However, due to its spatial attention-based design, changing the order of columns will usually – all else equal – change the forecast! The same applies to rows – it suddenly matters if I sort my context data by date, or by the associated user ID. As a side effect of this, having two samples with all features equivalent does no longer guarantee that their forecasts will be the same.
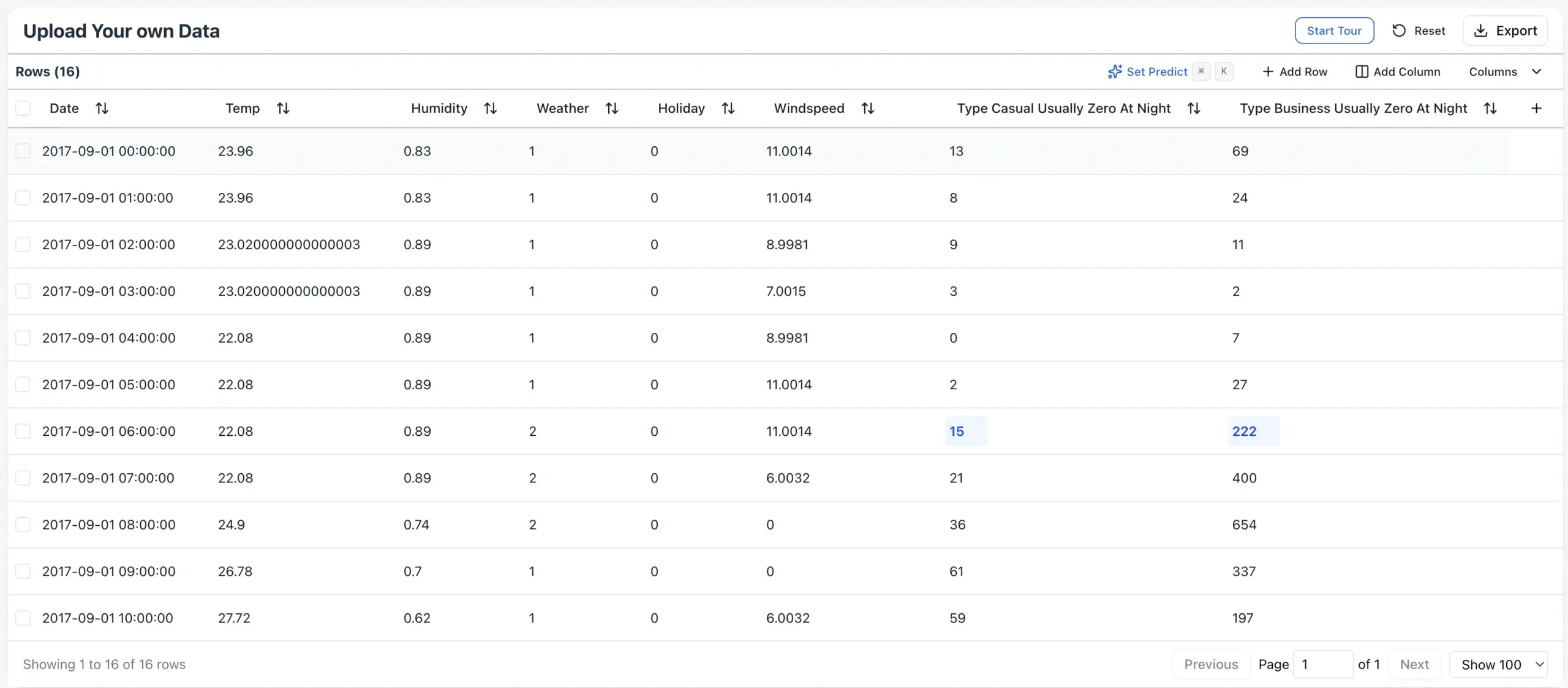

What’s even more important to note – The column names have a huge impact on the forecasted values, as their name and description is a direct input to RPT-1. While this allows transfer learning and capturing concepts about what a “price” column means, it also requires Data Scientists to accurately name their columns, ideally similar to the description used by SAP systems. In that sense, Data Scientists will also need to do “prompt engineering” on column names to find what delivers best results. In our experiences, it was not possible to inject domain knowledge (“less scooters will be rented at night”) into the forecast (yet). Maybe in the future we will get some type of system prompt for relational transformers in the future?
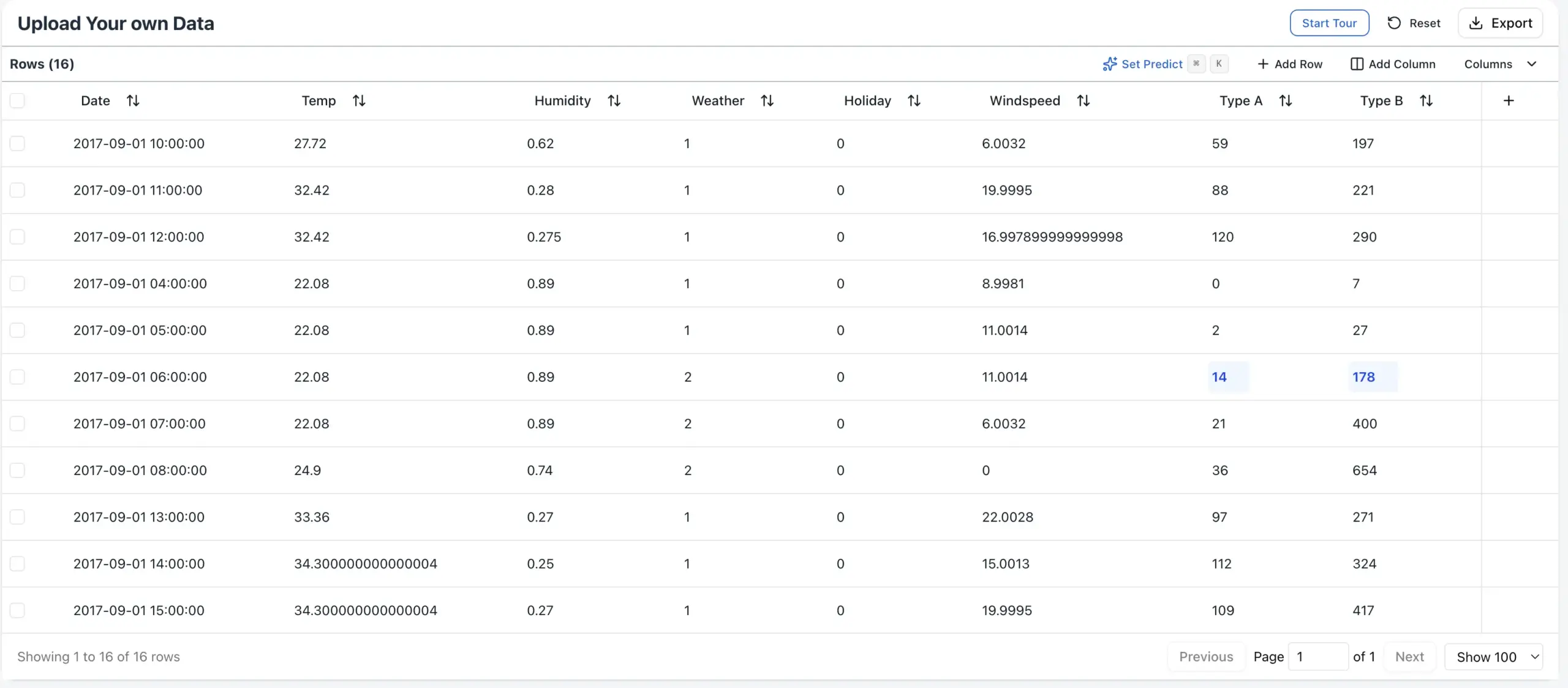
Even more importantly, RPT-1 embeds values inside categorical and textual columns. This means it should be able to capture “semantics” behind cell values, hopefully improving accuracies for tasks that rely (partly) on textual data. However, this means that Data Scientists now also need to experiment with how the categorical values are named – even if the ID values are the same, mapping categorical values will change the forecast outcome. This is another quirk that will not apply to traditional narrow AI approaches.
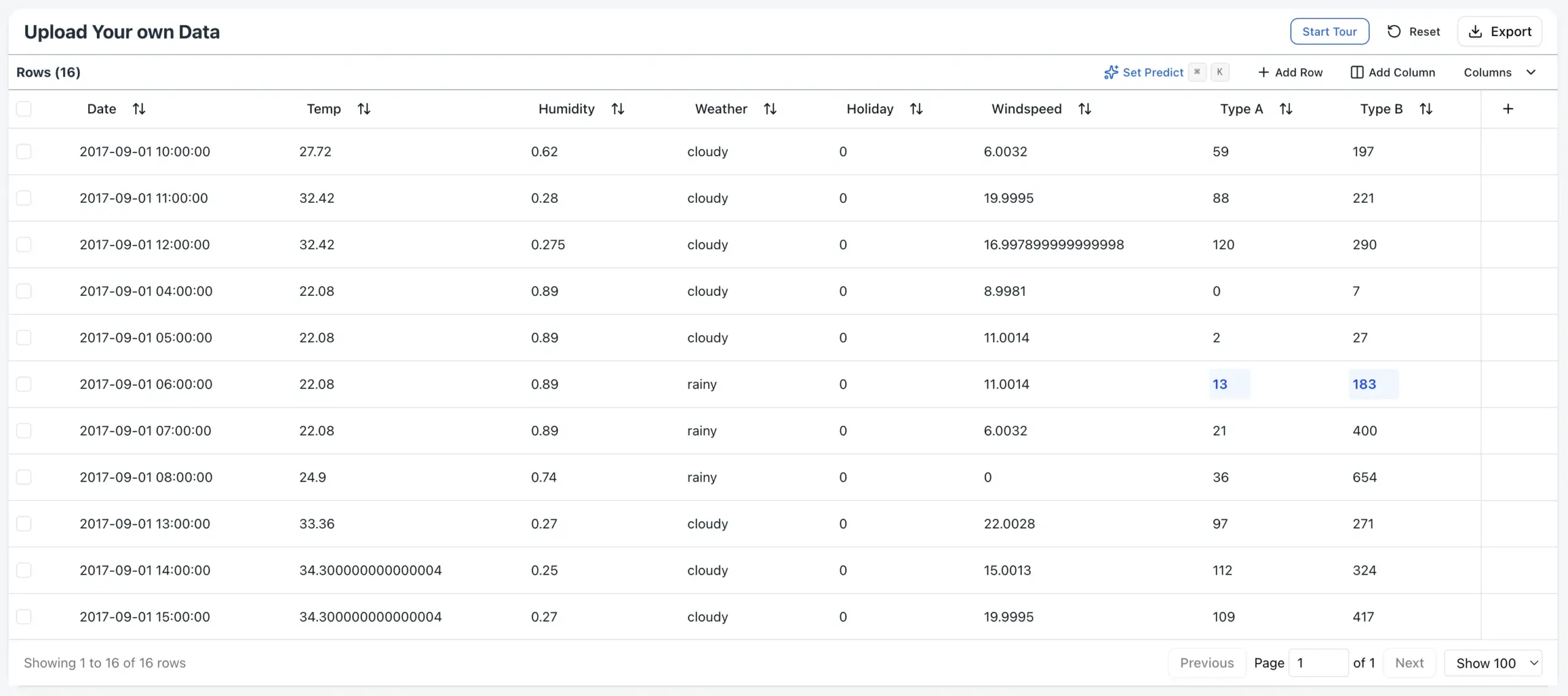
Even more so, a critical flaw (that also bothers similar models as TabPFN) is the limited context window (roughly 2.000 rows stated in the paper and as available in the playground). In many cases, this is far smaller than the training data available, so it is now a challenge upfront to decide which rows/samples from the full dataset need to be passed in as context to the current prediction task. This can be especially limiting for high-cardinality classification tasks: It is no longer possible to pass examples for each of the 15.000 material groups as a context for example.
Additionally, RPT-1 is “a single-table model”, which means that Data Scientists (for now) still need to ensure that this one table contains all relevant fields, including for example joining / aggregating data from linked tables. In that way, feature engineering across multiple tables is still a manual task, and requires good domain understanding. SAP has acknowledged that and is conducting research to include data from linked tables automatically.
Together with the issue mentioned above (row order matters), the Data Scientist now has to derive a heuristic on which historic data samples should be passed as context for each to-be forecasted sample! We have thus shifted the responsibility of Data Scientists from optimizing models to optimizing data, features, and taking care of context management – in a similar fashion as we have to carefully select the prompt and context for LLMs, using approaches such as Retrieval-Augmented Generation (RAG). Maybe we can even borrow the same approach from RAG for tabular data and maybe call it TRAG for tabular retrieval-augmented generation. Existing samples are embedded with a specialized relational embedding model, and when forecasting new samples we first select the 100 most similar known samples and pass these on to RPT-1 as context.
In addition, cells are “filled” one by one, so forecasting a lot of values will still take a fair amount of time, prohibiting the use for edge devices or ad-hoc tasks that require rapid decisions. Especially on the playground, there is a hard limit on maximum predicted cells as well as a rather strict rate limit.
As per SAP (and coinciding with our first evaluation results), SAP-RPT-1 also currently only supports classification and regression, no matching, recommendation or timeseries regression tasks. While these are on the SAP roadmap, it may take some time to fully leverage these capabilities on the full range of tasks that narrow AI models today successfully cover. Just a curious example: When tasked with predicting a time stamp between two given samples, it suggested the time stamp one year ahead.
Hype vs. Reality: A (slightly) critical view into SAP performance claims
SAP has suggested that their relational foundation-model may reduce “error rates by a factor of up to two”, e.g. when it comes to forecasts around materials, even when compared to fine-tuned narrow AI models trained on their customer data. Sadly, the linked paper does not support these claims directly, so we feel like some context is needed.
In their paper, the authors compare classification and regression tasks against some hand-crafted models (LGBM, XGBoost, CatBoost and auto-ML solutions such as AutoGluon) on a variety of publicly available collections of datasets (Appendix A.2, Table 3). Note that the paper calls RPT-1 by its former name, “ConTextTab”.
These datasets are:
- CARTE “has the particularity of being made of tables with high-cardinality string[s].”, i.e. exactly the type of “semantic” dataset that RPT-1 is set to excel in.
- OML-CC18 “a machine learning benchmark suite of 72 classification datasets carefully curated from the thousands of datasets on OpenML”
- OML-CTR23, “a curated collection of 35 regression problems available on OpenML”
- TabReD, “a new benchmark of industry-grade tabular datasets with temporally evolving and feature-rich real-world datasets”
- TALENT, “an Extensive Dataset Collection: Equipped with 300 datasets, covering a wide range of task types, size distributions, and dataset domains.”. The suffix “Tiny” means putting “focus on a subset containing 45 datasets that are representative of the overall performance of the baselines investigated in the original works”
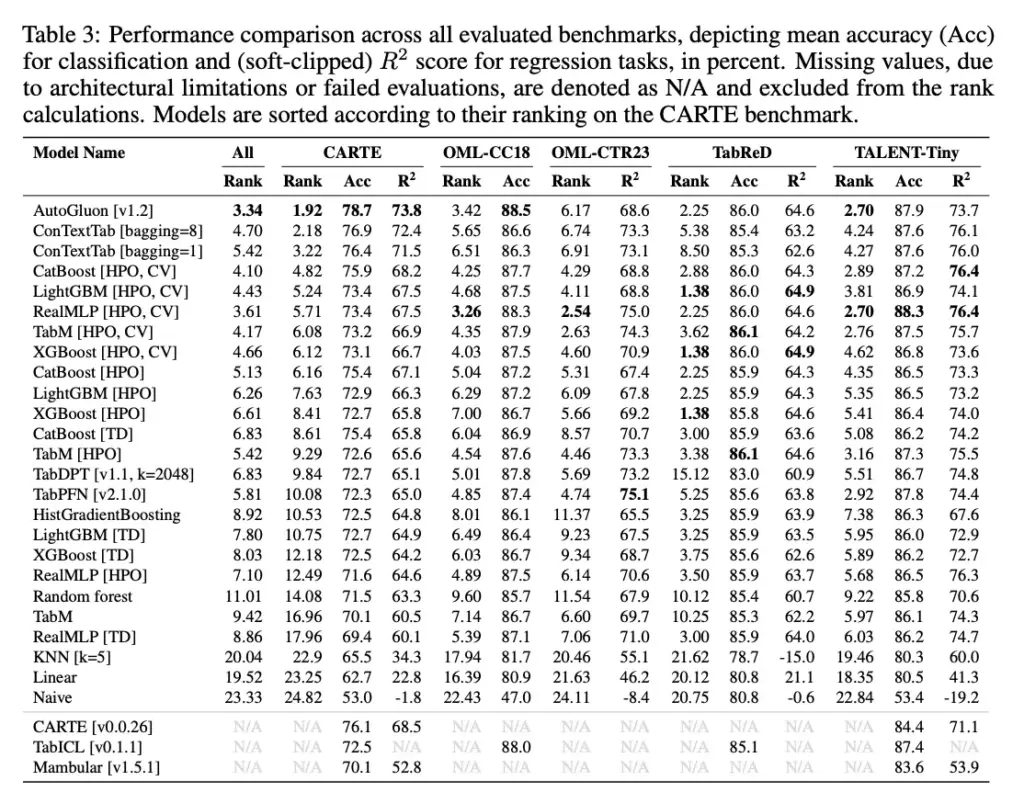
In this comparison, we can see that across all datasets SAP-RPT-1 has an average rank of 4.7 to 5.42 (depending on the hyperparameters used). Its skill seems to be mostly evident on the CARTE semantic benchmark, where it only slightly trails behind AutoGluon. On the other datasets, RPT-1 is usually in the midfield of scores. Based solely on these benchmarks alone, traditional narrow AI approaches as well as modern AutoML solutions, even without pretraining, are still frequently beating RPT-1. The sole question remains – What is the skill, time and compute required to derive a narrow AI model that beats the RPT-1 set baseline?
In that context, it is also important to check how these ranks evolve depending on the amount of available task-specific training data. Thankfully, the authors did this analysis as part of their paper, as shown below.
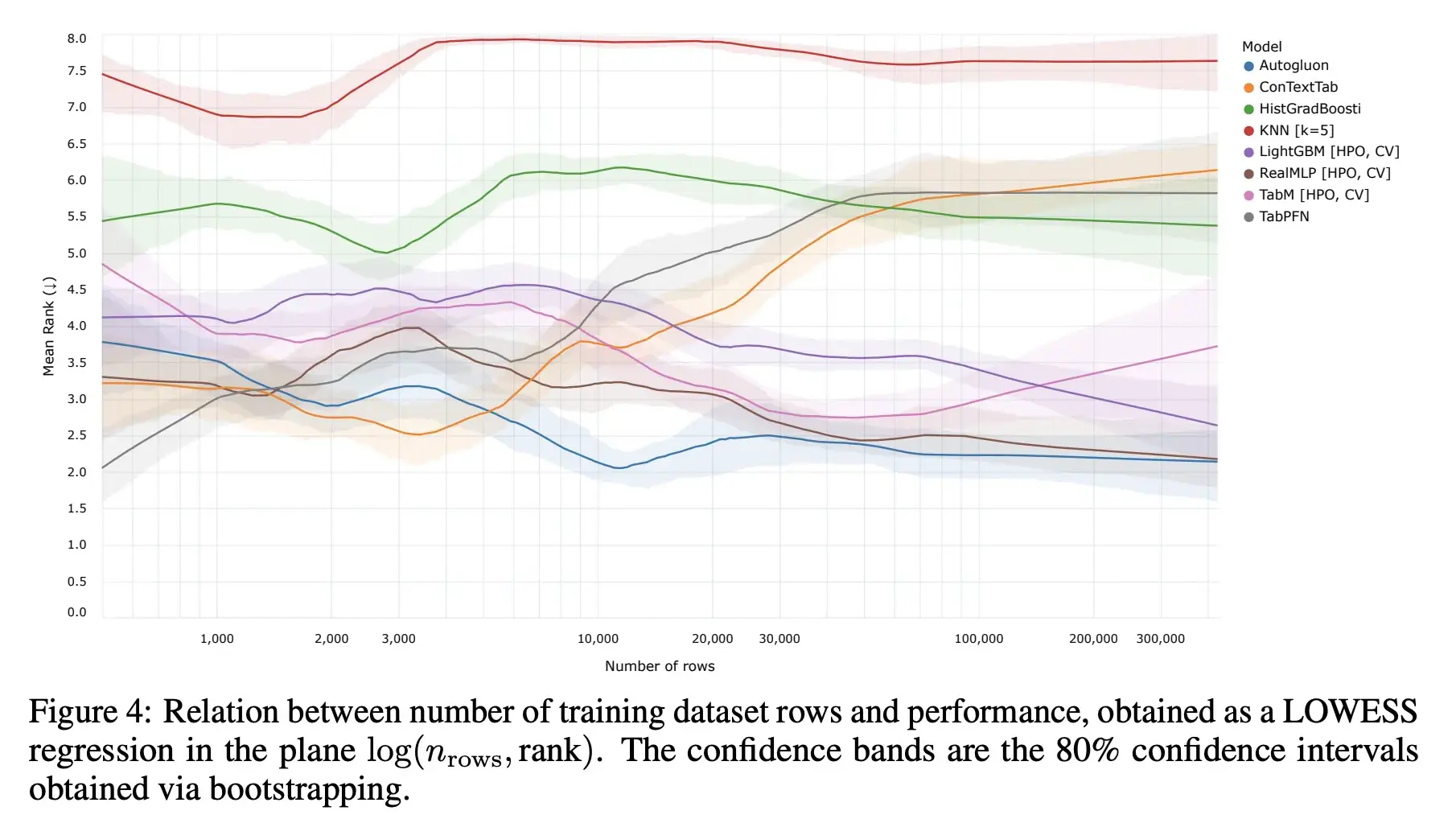
As we can see, for a limited set of training data (<5k samples), pre-trained contextual models (such as RPT-1/ConTextTab, TabPFN) are the top contenders due to their “general” knowledge impacting forecasts. If limited training data is available, these models will almost always beat handcrafted narrow AI models. Beyond 5k samples, Auto-ML solutions such as AutoGluon or NN-based tabular learners such as RealMLP are the top models, with gradient boosting algorithms such as LightGBM catching up as more and more data becomes available.
When should I (not) use SAP-RPT-1?
Our general recommendation: Always evaluate SAP-RPT-1 against known ground truth labels and against naive baseline models. For quick orientation, here are a few cases where we recommend using it – and others where we don’t.
Use SAP-RPT-1 if:
- training data is limited (less than 3-5k samples)
- the task builds on columns that are commonly available in existing SAP systems, and training data is still somewhat limited (less than 10k samples)
- the task heavily relies on semantic features, such as text values/descriptions, side by side with categorical data
- you don’t care about the best model and getting 80% there with less effort works for you
Don’t use SAP-RPT-1 if:
- you’re attempting time series forecasting, matching, recommendations, and the like
- you have enough training data
- reproducibility and explainability are a concern
- you have to run without internet access / on edge devices, or do real-time forecasts on larger datasets
In general, we are extremely happy to see SAP leverage their experience with AI and the vast amounts of available relational training data to offer the community a promising new approach to AI on relational data. Many of the shortcomings we currently see (and which thus reduce the scenarios where SAP-RPT-1 can be readily used today) are roadmap items and we are excited to see how these will be addressed and packaged into a well-rounded general purpose solution. In the long term, this has the possibility to enable Data Scientists with a less technical background to quickly deliver business value to stakeholders.
In that sense – no, “narrow” AI is not (yet?) dead – but relational foundation models will greatly change the way how we create business value with AI over the next two years. Interested in learning more about SAP AI Tooling? We’d be happy to talk.

